
Three days at the splendidly organised Twelfth International Conference on GeoComputation (Wuhan, China, 23rd-25th May) have provided a welcome opportunity for intellectual refreshment in the company of old friends and colleagues. Nevertheless an irritating feature of the meeting has been the apparently endless queue of speakers with diverse national and intellectual backgrounds all wanting to wax ever more lyrically on the need for new technologies in order to squeeze the value from rapidly overflowing reservoirs of social and physical data at ever finer scales of spatial and temporal resolution.
I was reminded somewhat of the old-fashioned idea of ‘throwing the baby out with the bathwater’, a multi-layered expression which conveys the general idea of a failure to distinguish the worthwhile from the worthless. In short, I’d like to hear a little bit less about all the new things we can do with our latest empirical goodies, and a bit more about how this helps us to build on the things to which many of us have already devoted the best of our careers.
It concerns me that the discipline of GeoComputation has the potential to become too easily harnessed to superficial readings of the ‘fourth paradigm’ rhetoric in which analytical pursuits are emasculated by the succubus of inductive reasoning. Quantitative geographers have been wrestling for the last sixty years with problems involving the generalisation and analytic representation of spatial problems. Social scientists could legitimately trace similar concerns back to Chicago in the 1920s, if not to scholars of the nineteenth century such as Ravenstein or Charles Booth. Typically such enquiry has wrestled gamely with the issue of a severe deficiency in Vitamin D(ata).
I’d be amongst the last to deny the possibilities for new styles of analysis with virtualised or real-time data, and the importance of emerging patterns of spatial and personal behaviour associated with new technologies such as social media. But surely we need to do this at the same as staying true to our roots. The last thing we need to do is to abandon our traditional concerns with the theory of spatial analysis when we finally have the information we need to start designing and implementing proper tests of what it means to understand the world around us. Wouldn’t it be nice to see a few more models out there (recalling that a model is no more or less than a concrete representation of theory) in which new sources of data are being exploited to test, iterate and refine real ideas which ultimately lead to real insights, and perhaps even real solutions to real problems?
Big Data Masochists must resist the Dominatrix of Social Theory
Here at the AAG in Los Angeles it has been good to witness at first hand the continued vibrancy and diversity of geographical inquiry. In particular, themes such as Agent-based Modelling, Population Dynamics, and CyberGIS have been well represented alongside sessions on Social Theory, Gender and Cultural and Political Ecology. At Friday’s sessions on big data and its limits (“More data, more problems”; “the value of small data studies”) I learned, however that the function of geography is to push back against those who worship at the atheoretical altar of empirical resurrection, while simultaneously getting off on what one delegate branded the ‘fetishisation of numbers’. The ‘post-positivists’ it seems are far too sophisticated to be seduced by anything so sordid as numerical evidence, while poor old homo quantifactus still can’t quite see past the entrance of his intellectual cave.
Exactly who is being raped here is a moot question however. ( For those unfamiliar with the reference to the ‘rape of geographia’, see the cartoon here: http://www.quantamike.ca/pdf/94-11_MapDiscipline.pdf). Speaking as someone who has spent 30 years in the UK working with GIS, simulation and geocomputation, it is hard to escape the conclusion that the dominatrix of social theory has deployed her whips and chains with ruthless efficiency. Can we therefore be clear on a couple of points. First, the role of geography (and geographers) is not to push back against specific approaches, but to provide the means for spatial analysis (and theory) which complements other (non-spatial) perspectives. Second, whether my data is bigger than your data is not the issue, and any argument which couches the debate in terms of ‘the end of theory’ (cf Anderson, 2008 – http://www.wired.com/science/discoveries/magazine/16-07/pb_theory) is missing the point. New data sources provide immense opportunity for creative approaches to the development of new ‘theories’ of spatial behaviour, and to the testing and refinement of existing theories (which I probably like to call ‘models’, although I’ve not evolved to become a post-positivist yet).
The challenges are tough. It is possible that some current attempts to navigate the big data maze lack rigour because the sub-discipline is so new, but also after 30 years of chronic under-investment in quantitative geography our community struggles to access the necessary skills. Far from pushing back against the mathematicians, engineers and other scientists it may be necessary to engage with these constituencies over a long period of time to our mutual benefit. Observations about what any of us might like to do with numbers in the privacy of our own offices and hotel rooms are a less than helpful contribution to the debate.
Virtual Globes
It’s been very quiet over Easter and I’ve been meaning to look at 3D visualisation of geographic data for a while. The aim is to build a framework for visualising all the real-time data we have for London without using Google Earth, Bing Maps or World Wind. The reason for doing this is to build a custom visualisation that highlights the data rather than being overwhelmed by the textures and form of the city as in Google Earth. Basically, to see how easy it is to build a data visualisation framework.
After quite a bit of experimentation, the results are shown below:
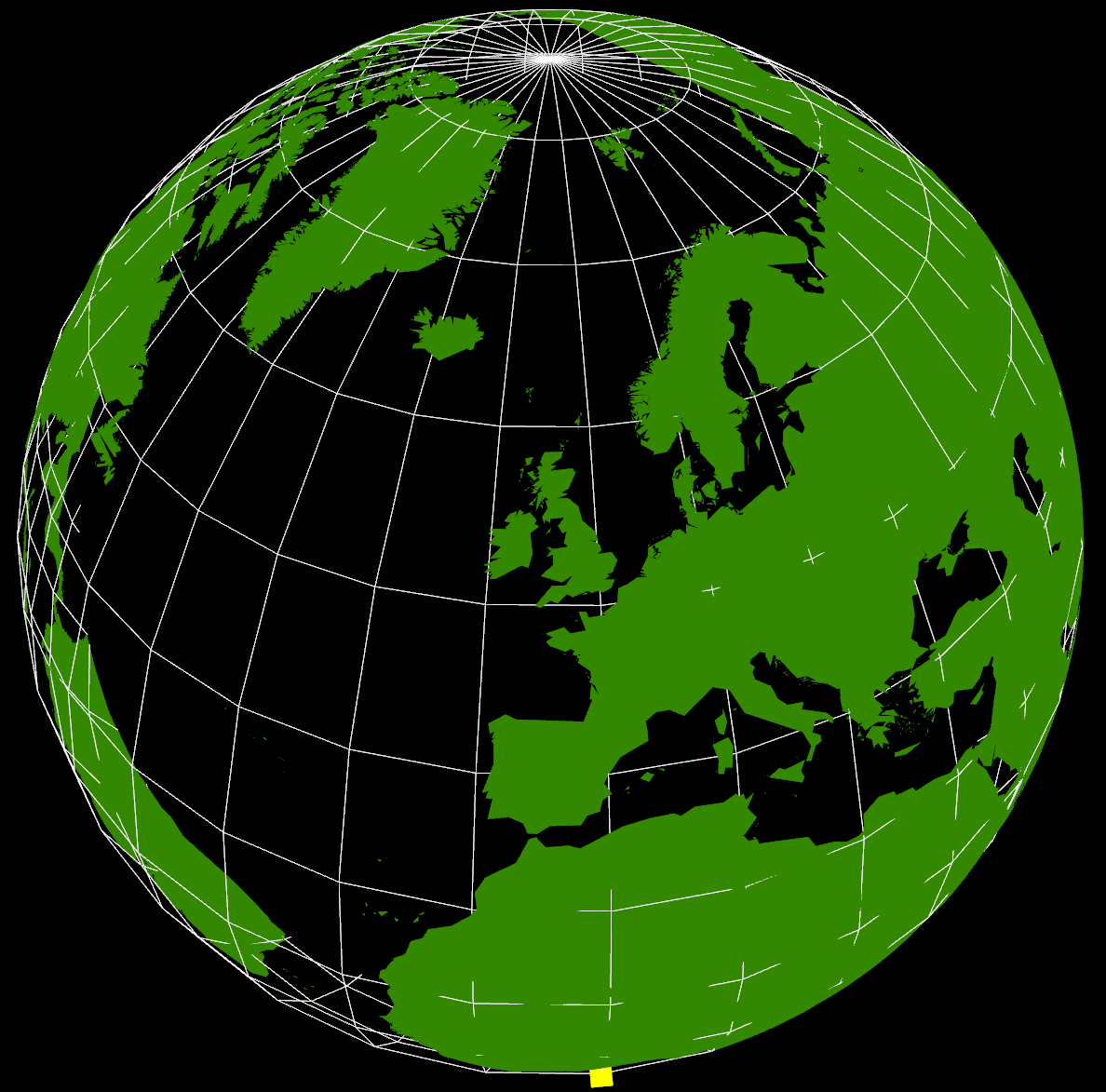
The yellow cube at the extreme southern point is marking (0,0) (lat,lon) as a reference. It’s also possible to see right through the Earth as I haven’t put any water in yet, but that’s not immediately apparent in this screenshot. The globe can be rotated and zoomed using the mouse, so it’s possible to see an area in more detail.
The way this has been constructed is as a WebGL application using THREE.JS running in Chrome. Originally, I started looking at using WebGL directly as I wanted to be able to create custom shaders, but in the end decided that programming at the higher level of abstraction using THREE.JS and a scene graph was going to be a lot faster to develop.
Where I got stuck was with the countries of the World geometry, and what you see in the graphic above still isn’t correct. I’ve seen a lot of 3D visualisations where the geometry sits on a flat plane, and this is how the 3D tubes visualisation that I did for the XBox last year worked. Having got into lots of problems with spatial data not lining up, I knew that the only real way of doing this type of visualisation is to use a spherical model. Incidentally, the Earth that I’m using is a sphere using the WGS84 semi-major axis, rather than the more accurate spheroid. This is the normal practice with data at this scale as the error is too small to notice.
The geometry is loaded from a GeoJSON file (converted from a shapefile) with coordinates in WGS84. I then had to write a GeoJSON loader which builds up the polygons from their outer and inner boundaries as stored in the geometry file. Using the THREE.JS ‘Shape’ object I’m able to construct a 2D shape which is then extruded upwards and converted from the spherical lat/lon coordinates into Cartesian 3D coordinates (ECEF with custom axes to match OpenGL) which form the Earth shown above. This part is wrong as I don’t think that THREE.JS is constructing the complex polygons correctly and I’ve had to remove all the inner holes for this to display correctly. The problem seems to be overlapping edges which are created as part of the tessellation process, so this needs more investigation.
What is interesting about this exercise is the relationship between 3D computer graphics and geographic data. If we want to be able to handle geographic data easily, for example loading GeoJSON files, then we need to be able to tessellate and condition geometry on the fly in the browser. This is required because the geometry specifications for geographic data all use one outer boundary and zero or more inner boundaries to represent shapes. In 3D graphics, this needs to be converted to triangles, edges and faces, which is what the tessellation process does. In something like Google Earth, this has been pre-computed and the system loads conditioned 3D geometry directly. I’m still not clear which approach to take, but it’s essential to get this right to make it easy to fit all our data together. I don’t want to end up in the situation with the 3D Tubes where it was written like a computer game with artwork from different sources that didn’t line up properly.
The real reason for building this system is shown below:

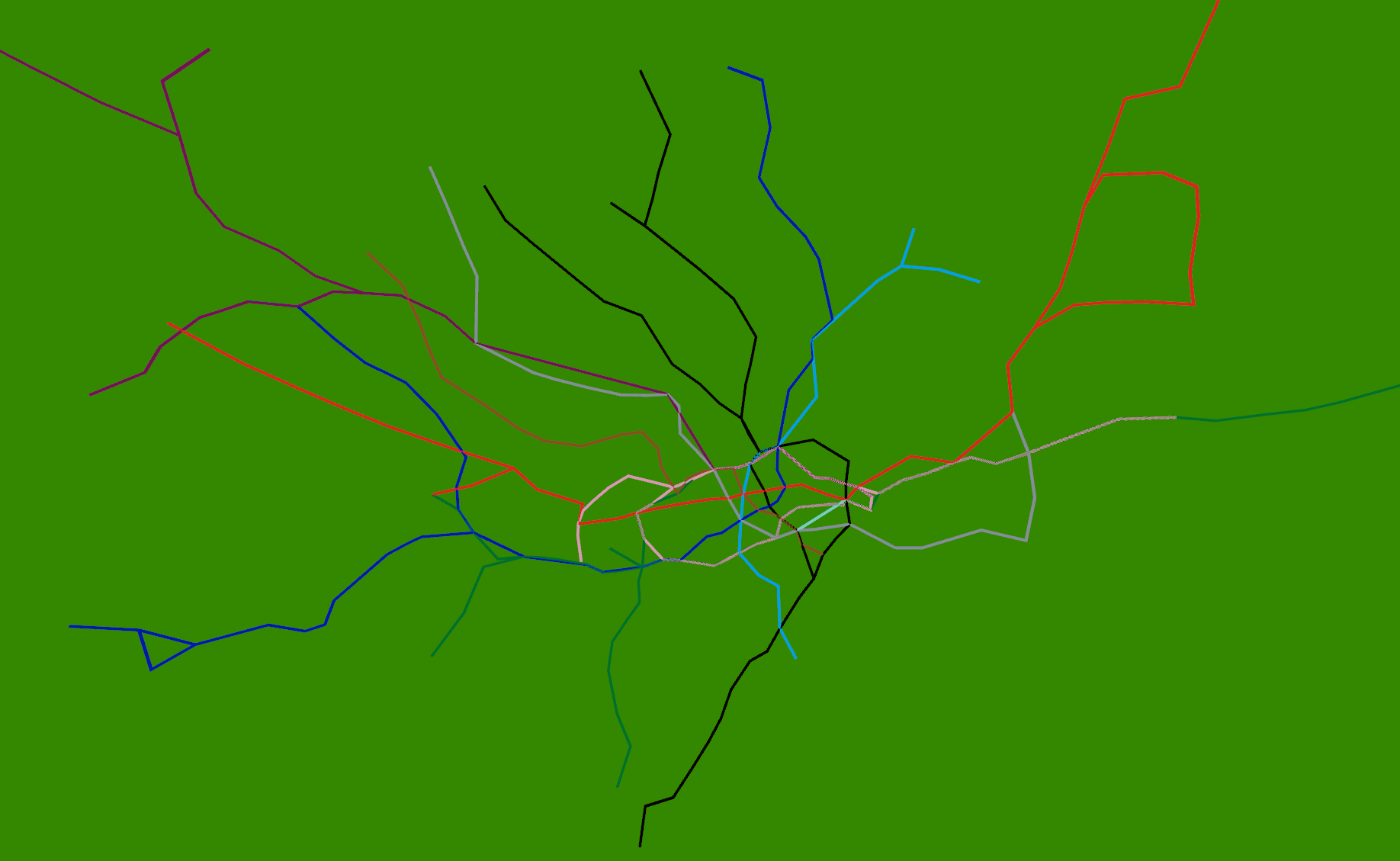
Strangely enough, adding the 3D tube lines with real-time tubes, buses and trains is easy once the coordinate systems are worked out. The services to provide this information already exist, so it’s just a case of pulling in what is relatively simple geometry. The road network and buildings are available from the OS Free data release, so, with the addition of Lidar data, we could build another (real-time) Virtual London model.
Just for the record, it took about 4 days to get this working using the following tools: Visual Studio 2010 C# and C++, Autodesk 3DS Max 2012 and the FBX exporter, Python 2.6, NetBeans Java and Geotools 8, Quantum GIS, Chrome Developer Tools
Cities as Operating Systems
The idea of cities mirroring computer operating systems has been around for a while (see: http://teamhelsinki.blogspot.co.uk/2007/03/city-as-operating-system.html ), but recent events have made me wonder whether this might be about to become more important. Cities are systems in exactly the same way that complex computer systems are, although how cities function is a black box. Despite that difference, computer systems are now so big and complex that understanding how the whole system works is incomprehensible and we rely on monitoring, which is how we come back to the city systems. Recently, we had a hardware failure on a virtual machine host, but in this case I happened to be looking at the Trackernet real-time display of the number of tubes in London. This alerted me to the fact that something was wrong, so I then switched to the virtual machine monitoring console and diagnosed the failure. We were actually out of the office at the time, so the publicly accessible tube display was easier to access than the locked down secure console for the hardware. The parallels between the real-time monitoring of a server cluster and real-time monitoring of a city system are impossible to ignore. Consider the screenshot below:
![]()
Screenshot from an iPad showing a stream graph of the number of tubes running in London on Friday 22nd and Saturday 23rd March 2013.
We could very easily be looking at CPU load, disk or network bandwidth for a server, but it happens to be the number of tubes running on the London Underground. Points 1 and 2 show a problem on the tube network around 3PM on Friday. It’s not very easy to tell from this visualisation, but the problem is on the Piccadilly line and then the Jubilee line. However, the purpose of this display is to alert the user to any problems which they can then diagnose further. Point 3 is not so easy to detect, but the straight lines suggest missing data. Going back to the original files, everything appears normal and all data is being logged, so this could be an API or other network failure that rectified itself. Point 4 is similar, but this can be explained as a Saturday morning outage for maintenance to prevent the problem that we saw on Wednesday happening again.
It is this symbiotic relationship between the real-time monitoring of city systems and computer systems that is really interesting. We are logging a lot more data than is shown on this graph, so the key is to work out what factors we need to be looking at to understand what is really happening. Add a spatial element to this and the system suddenly becomes a whole lot more complicated.
To finish off with, here is view of the rail network at 12pm on 25 March 2013 (another snow day in the North of the country). The similarity between this view and and a seismograph is apparent, but what is being plotted is average minutes late per train. The result is very similar to a CPU or disk activity graph on a server, but minute by minute we’re watching trains running.

Links
http://teamhelsinki.blogspot.co.uk/2007/03/city-as-operating-system.html
http://www.smartplanet.com/blog/smart-takes/london-tests-out-smart-city-operating-system/26266
Lots and Lots of Census Maps (part 2)
My last post on the Census Maps got as far as running a simple comparison of every combination of every possible map at LSOA level to obtain a similarity metric. There are 2,558 possible variables that can be mapped, so my dataset contains 6,543,364 lines. I’ve used the graph from the last post to set a cut off of 20 (in RGB units) to select only the closest matches. As the metric I’m using is distance in RGB space, it’s actually a dissimilarity metric, so 0 to 20 gives me about 4.5% of the top matches, resulting in 295,882 lines. Using an additional piece of code I can link this data back to the plain text description of the table and field so I can start to analyse it.
The first thing I noticed in the data is that all my rows are in pairs. A matches with B in the same way that B matches with A and I forgot that the results matrix only needs to be triangular, so I’ve got twice as much data as I actually needed. The second thing I noticed was that most of the data relates to Ethnic Group, Language and Country of Birth or Nationality. The top of my data looks like the following:
| 0.1336189 | QS211EW0094 | QS211EW0148 | (Ethnic Group (detailed)) Mixed/multiple ethnic group: Israeli AND (Ethnic Group (detailed)) Asian/Asian British: Italian |
| 0.1546012 | QS211EW0178 | QS211EW0204 | (Ethnic Group (detailed)) Black/African/Caribbean/Black British: Black European AND (Ethnic Group (detailed)) Other ethnic group: Australian/New Zealander |
| 0.1546012 | QS211EW0204 | QS211EW0178 | (Ethnic Group (detailed)) Other ethnic group: Australian/New Zealander AND (Ethnic Group (detailed)) Black/African/Caribbean/Black British: Black European |
| 0.1710527 | QS211EW0050 | QS211EW0030 | (Ethnic Group (detailed)) White: Somalilander AND (Ethnic Group (detailed)) White: Kashmiri |
| 0.1883012 | QS203EW0073 | QS211EW0113 | (Country of Birth (detailed)) Antarctica and Oceania: Antarctica AND (Ethnic Group (detailed)) Mixed/multiple ethnic group: Peruvian |
| 0.1883012 | QS211EW0113 | QS203EW0073 | (Ethnic Group (detailed)) Mixed/multiple ethnic group: Peruvian AND (Country of Birth (detailed)) Antarctica and Oceania: Antarctica |
| 0.1889113 | QS211EW0170 | QS211EW0242 | (Ethnic Group (detailed)) Asian/Asian British: Turkish Cypriot AND (Ethnic Group (detailed)) Other ethnic group: Punjabi |
| 0.1925942 | QS211EW0133 | KS201EW0011 | (Ethnic Group (detailed)) Asian/Asian British: Pakistani or British Pakistani AND (Ethnic Group) Asian/Asian British: Pakistani |
The data has had the leading diagonal removed so there are no matches between datasets and themselves. The columns show match value (0.133), first column code (QS211EW0094), second column code (QS211EW0148) and finally the plain text description. This takes the form of the Census Table in brackets (Ethnic Group (Detailed)), the column description (Mixed/multiple ethnic group: Israeli), then “AND” followed by the same format for the second table and field being matched against.
It probably makes sense that the highest matches are ethnicity, country of birth, religion and language as there is a definite causal relationship between all these things. The data also picks out groupings between pairs of ethnic groups and nationalities who tend to reside in the same areas. Some of these are surprising, so there must be a case for extracting all the nationality links and producing a graph visualisation of the relationships.
There are also some obvious problems with the data which you can see by looking at the last line of the table above: British Pakistani matches with British Pakistani. No surprise there, but it does highlight the fact that there are a lot of overlaps between columns in different data tables containing identical, or very similar data. At the moment I’m not sure how to remove this, but it needs some kind of equivalence lookup. This also occurs at least once on every table as there is always a total count column that matches with population density:
| 0.2201077 | QS101EW0001 | KS202EW0021 | (Residence Type) All categories: Residence type AND (National Identity) All categories: National identity British |
These two columns are just the total counts for the QS101 and KS202 tables, so they’re both maps of population. Heuristic number one is: remove anything containing “All categories” in both descriptions.
On the basis of this, it’s probably worth looking at the mid-range data rather than the exact matches as this is where it starts to get interesting:
| 10.82747 | KS605EW0020 | KS401EW0008 | (Industry) A Agriculture, forestry and fishing AND (Dwellings, Household Spaces and Accomodation Type) Whole house or bungalow: Detached |
| 10.8299 | QS203EW0078 | QS402EW0012 | (Country of Birth (detailed)) Other AND (Accomodation Type – Households) Shared dwelling |
To sum up, there is a lot more of this data than I was expecting, and my method of matching is rather naive. The next iteration of the data processing is going to have to work a lot harder to remove more of the trivial matches between two sets of data that are the same thing. I also want to see some maps so I can explore the data.
Lots and Lots of Census Maps
I noticed recently that the NOMIS site has a page with a bulk upload of the latest release of the 2011 Census Data: http://www.nomisweb.co.uk/census/2011/bulk/r2_2
As one of the Talisman aims is to be able to able to handle data in datastores seamlessly, I modified the code that we used to mine the London Datastore and applied the same techniques to the latest Census data. The first step is to automatically create every possible map from every variable in every dataset, which required me uploading the new 2011 Census Boundary files to our server. This then allows the MapTubeD tile server to build maps directly from the CSV files on the NOMIS site. Unfortunately, this isn’t completely straightforward as I had to build some additional staging code to download the OA zip file, then split the main file up into MSOA, LSOA and OA files as all the data is contained in a single file.
The next problem was that running a Jenks stratification on 180,000 records at OA level is computationally intensive, as is building the resulting map. The Jenks breaks can be changed to Quantiles which are O(n) as opposed to O(n^2), but in order to build this many maps in a reasonable time I dropped the geographic data down to LSOA level. This is probably a better option for visualisation anyway and only has 35,000 areas.
The resulting maps look similar to the following:
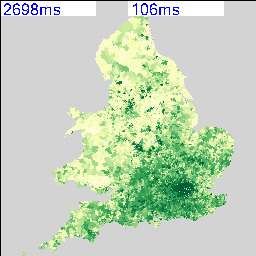
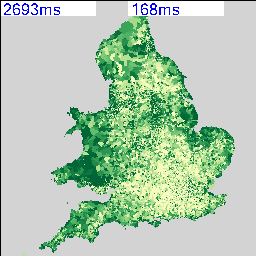
I’m deliberately not saying what these maps show at the moment and you can’t tell from the numbers as that’s part of the debugging code telling me how long they took to render. As there are 2,558 of these maps possible from the data, knowing that this can be done in a reasonable amount of time and that I can leave it running overnight is quite important. My quick calculation based on a 27″ iMac doing about 4 Mips seems to work out about right.
The two maps above show an interesting spatial variation, so the next step was to use a spatial similarity metric on every combination of two maps to generate a correlation matrix containing 2,558 x 2,558 cells. Not knowing whether this was going to work and also being worried about the size of the data that I’m working with, I decided to use a simple RGB difference squared function. The maps are rendered to thumbnails which are 256 x 256 pixels, so the total number of operations to calculate this is going to be (2558*2558)/2 * 65536/4 MIPS, or about 15 hours times however long a single RGB comparison takes.
The result of running this over night is a file containing 6,543,364 correlation scores. What I wanted to do first was to plot this as a distribution of correlation scores to see if I could come up with a sensible similarity threshold. I could derive a statistically significant break threshold theoretically, but I really wanted to look at what was in the data as this could show up any problems in the methodology.
The aim was to plot a cumulative frequency distribution, so I need a workflow that can clean the data and sort 6 million values, then plot the data. There were some nightmare issues with line endings that required the initial clean process to remove them, using “egrep -v “^$” original.csv > cleaned.csv”. My initial thoughts were to use Powershell to do the clean and sort, but it doesn’t scale to the sizes of data that I’m working with. The script to do the whole operation is really easy to code in the integrated environment, but was taking far too long to run. This meant a switch to a program I found on Google Code called “CSVFix“. The operation is really simple using the command line:
csvfix sort -f 5:AN imatch.csv > imatch-sorted.csv
This sorts column 5 ascending (A) using a numeric (N) match and doesn’t take a huge amount of time. The final step is to plot the data and see what I’ve got. This was done using GNUPlot as the data is too big to load into Excel or Matlab. In fact, the only binaries available for GNUPlot are x86, so I was worried I was going to have to build an x64 version to handle the data, but this turned out to be unnecessary. The following commands plot the data:
set datafile separator “,”
plot ‘imatch-sorted.csv’ using 5
And the final graph looks like this:
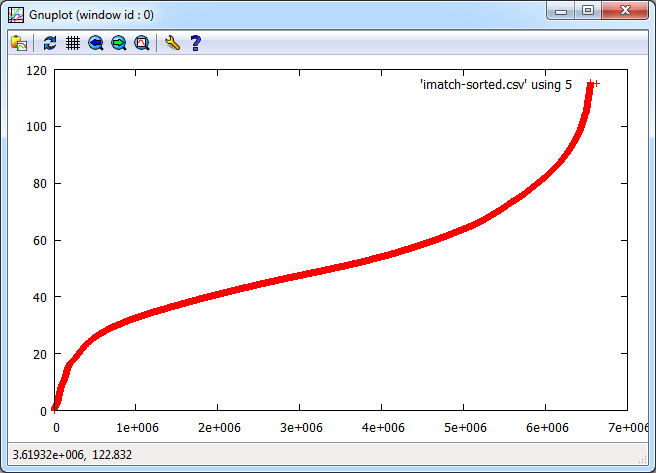
The “S-Curve” that results is interesting as the Y-Axis shows difference with zero being identical and 120 being very different. The X-Axis shows the number of maps that match with the Y-Axis difference or better, so it’s a cumulative plot of similarity. Units for the Y-Axis are RGB intensity, with the X-Axis having no units as it’s a count. There are 2558 maps that match with themselves with zero difference, but up to about 20, there appears to be a linear relationship followed by a turning point and another linear section with reduced gradient until the difference starts to increase rapidly.
Most of this can be explained by the fact that all the maps are of England and so anything in the sea is always going to match on every map regardless. As I explained at the beginning, this is really an exploration of the workflow and methodology, so there are a number of problems with it. The ultimate aim is to show how all the data is related, so similarity, spatial weighted similarity, clustering and comparisons between gridded data, areas and rendered maps all need to be explored.
How many social scientists does it take to transform a lightbulb?
I was invited to contribute to a round-table meeting to discuss Computational and Transformational Social Science which took place at the University of Oxford on Monday 18th February. In the background papers for the meeting I learned that the International Panel for the Review of the e-Science Programme, commissioned by the UK Research Councils in 2009, had reported that:
“Social science is on the verge of being transformed … in a way even more fundamental than research in the physical and life sciences”.
It continues in a similarly reasonable vein:
“… the ability to capture vast amounts of data on human interactions in a manner unimaginable from traditional survey data and related processes should, in the near term, transform social science research … (t)he impact of social science on both economic and social policy could be transformed as a result of new abilities to collect and analyse real-time data in far more granular fashion than from survey data.”
In this context, the participants were asked to comment (briefly!) on three questions:
- What is the state of the art in ‘transformative’ digital (social) research?
- Are there examples of transformative potential in the next few years?
- What are the special e-Infrastructural needs of the social science community to achieve that potential?
My first observation about these questions is that they are in the wrong order. Before anything else we need to think about examples where digital research can really start to make a difference. I would assert that such cases are abundant in the spatial domains with which TALISMAN concerns itself. For instance the challenge of monitoring individual movement patterns in real-time, of understanding and simulating the underlying behaviour, and translating this into benefit, such as in policy arenas relating to health, crime or transport.
In relation to the state of the art I am somewhat less sanguine. My notes read that ‘the academic sector is falling behind every day’ – think Tesco Clubcard, Oystercard, SmartSteps, even Twitter as data sets to which our community either lacks access or is in imminent danger of losing access. How do we stay competitive with the groups who own and control these data? In relation to current trends in funding I ask whether it is our destiny to become producers of the researchers but no longer of the research itself?
As regards e-Infrastructure, my views are if anything even more pessimistic. After N years of digital social research in the UK (where N>=10) are there really people who still believe that the provision of even more exaflops of computational capacity is key? While data infrastructure could be of some significance, the people issues remain fundamental here – how do we engage a bigger community in these crucial projects (and why have we failed so abjectly to date?), and how do we fire the imagination of the next generation of researchers to achieve more?
Mark 1 Spider Bee
Following on from the Hex Bug Spiders that we were running at Leeds City Museum, I have modified our third spider to use an XBee module for wireless control via a laptop using the 802.15.4 protocol for mesh networks. This gives me a two way channel to the spider, so we can now add sensors to it, or even a camera module.

The following clips show the spider walking (turn the sound on to really appreciate these):
Construction details will follow in a later post, but the way this has been constructed is to take a regular Hex Bug spider and remove the carapace containing the battery cover and battery box. The three securing screws are then used to mount some prototyping board onto the body of the hex bug. Two of these white plastic bits can be seen in the picture attaching the board to the green plastic case. The first board contains a Lithium Ion camera battery (3.7v 950mAH). On top of that is a thin black plastic rectangle secured using four 2mm bolts at the corners of the battery board. Onto this is mounted two further prototype boards containing the H-Bridge driver (lower) and XBee board (upper). The upper board has a further daughter board attached to take the XBee module which sits at the very top along with the red and green LEDs. The blinking red LED shows that the network is connected while the green LED indicates received packets. The main reason for having the XBee plugged in to this adapter is to convert the 2mm spacing pins of the XBee to the 0.1 inch holes of the prototype board. The XBee adapter is actually plugged in to a chip holder that is mounted on the top board. Ideally I would have re-used the motor driver electronics of the existing Hex Bug controller, but it turned out to be too fiddly to modify, so it was easier just to construct new circuitry. This is only a prototype, but using a double-sided PCB it would be quite easy to mount everything onto a single board that would sit neatly above the battery.
In terms of software, the controller is built using Java and the XBee API that can be downloaded from Google Code: http://code.google.com/p/xbee-api/
The coordinator XBee connects to the laptop via a USB cable and is plugged in to an XBee serial adapter. This runs in API mode (escaped) while the router XBee on the spider is in AT mode. Both use the Series 2 firmware with the coordinator sending commands to the spider using Remote AT command packets (which are only available in API mode).
Now that this is running, we have the potential to run more than two spiders at once so we can build a more complex agent simulation. With the code all using Java, there is the potential to link this to NetLogo, but the missing link is the vision software which I’m still working on.
D3 Graph Problems
My last post on the delays caused by the snow contained a comment about a bug in the D3 library. Not wanting to just leave this, I’ve done some more testing with the latest D3 code. As can be seen from the graph below, something corrupts the x coordinate in the SVG path:
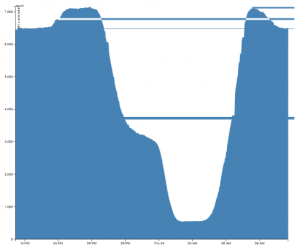
On further inspection, the horizontal lines are caused by the following anomaly in the SVG path element:
<path d=”M890,69.15851272015652………….
L774.8666471048152,5.417948001118248
L773.0392824747554,3.3994967850153444
L771.201277694171,0.6374056471903486
L-13797062.104351573,5.736650824713479
L767.5585693674684,5.736650824713479
L765.6888979556953,12.004473022085563
L763.9054848634413,12.004473022085563
L762.0744956782887,12.004473022085563
Looking at line 4, a large negative number has crept into the X coordinate list, which is giving the horizontal lines.
I’ve verified that the original data is correct, I’m using the v3 release version of D3 and exactly the same thing happens with IE9, Chrome and Firefox. This graph has 486 data values, so it’s not exactly massive.
I’ll post more once I’ve tracked the problem down.
Real Time City Data
With the recent snow in London, we’ve been looking at real-time sources of transport data with a view to measuring performance. The latest idea was to use flight arrivals and departures from Heathrow, Gatwick and City to measure what effect snow had on operations. The data for Heathrow is shown below:
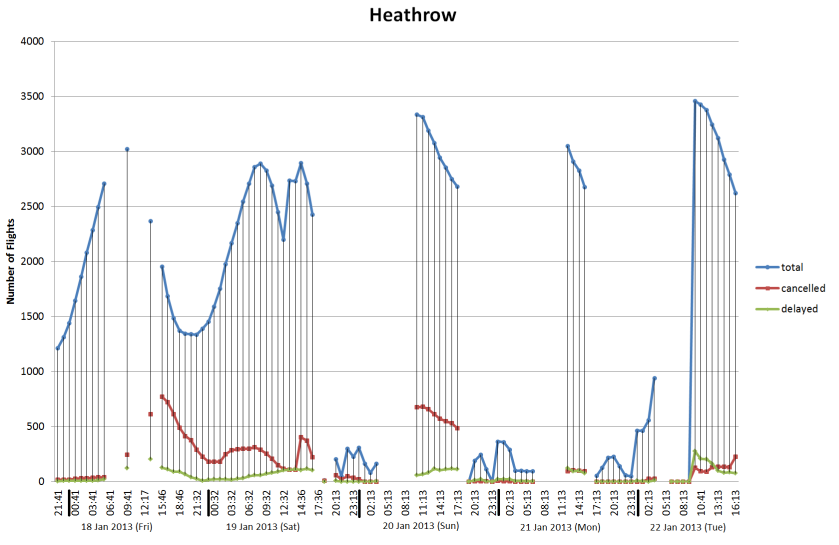
Arrivals and departures data for Heathrow from 17 Jan 2013 to 22 Jan 2013
This is our first attempt with this type of flights data and it shows how difficult it is to detect the difference between normal operation and when major problems are occurring. We’ve also got breaks in the data caused by the sampling process which don’t help. Ideally, we would be looking at the length of delays which would give a finer indication of problems, but this is going to require further post processing. After looking at this data, it seems that we need to differentiate between when the airport is shut due to adverse weather, so nothing is delayed because everything is cancelled and the other situation where they’re trying to clear a backlog after re-opening.
If we look at the information for Network Rail services around London, then the picture is a lot easier to interpret:
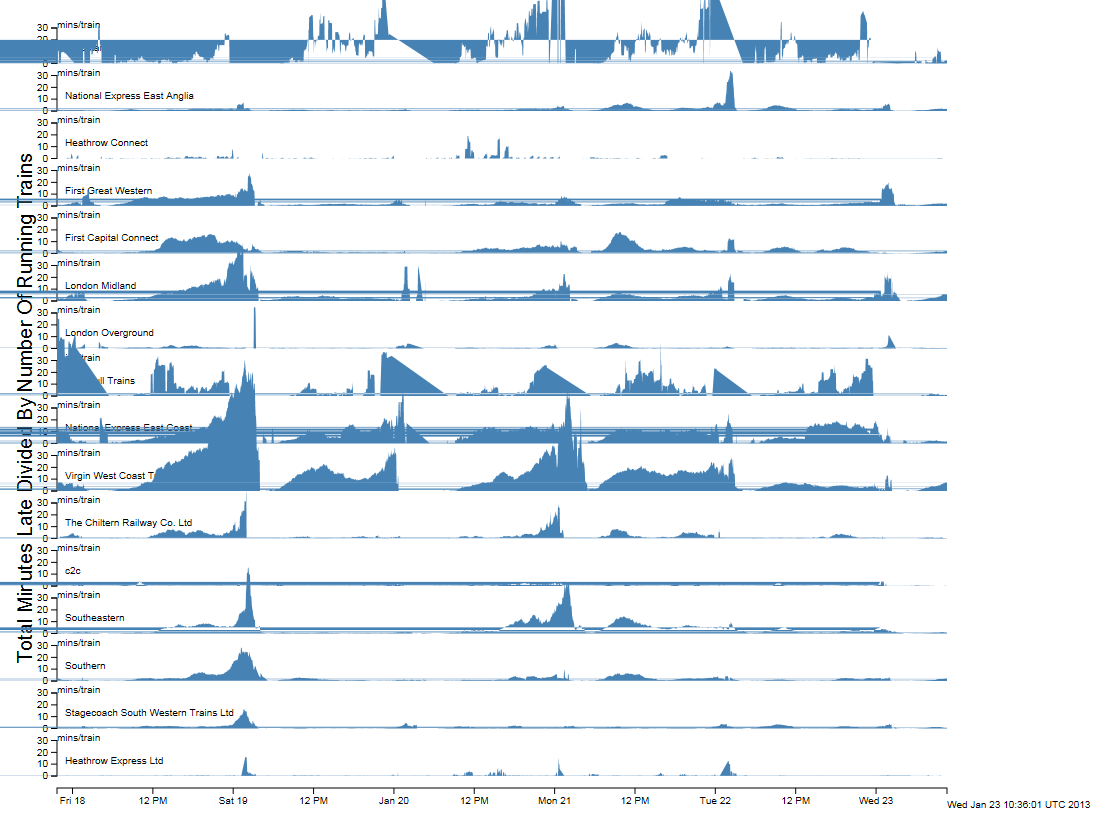
Network Rail data for all trains within the London area from 17 January 2013 to 23 January 2013
The graphs plot total late minutes divided by total number of trains, or average late minutes per running train. This gives a very good indicator of when there are problems. Unfortunately, there appears to be a bug in the D3 library which is causing the horizontal lines across the graphs. The situation with South West trains is interesting because it looks from the graph as though they didn’t have any problems with the snow. In reality, they ran a seriously reduced service so the number of trains is not what it should be. This needs to be factored in to any metric we come up with for rail services to cope with the situation where the trains are running, but people can’t get on them because they are full.
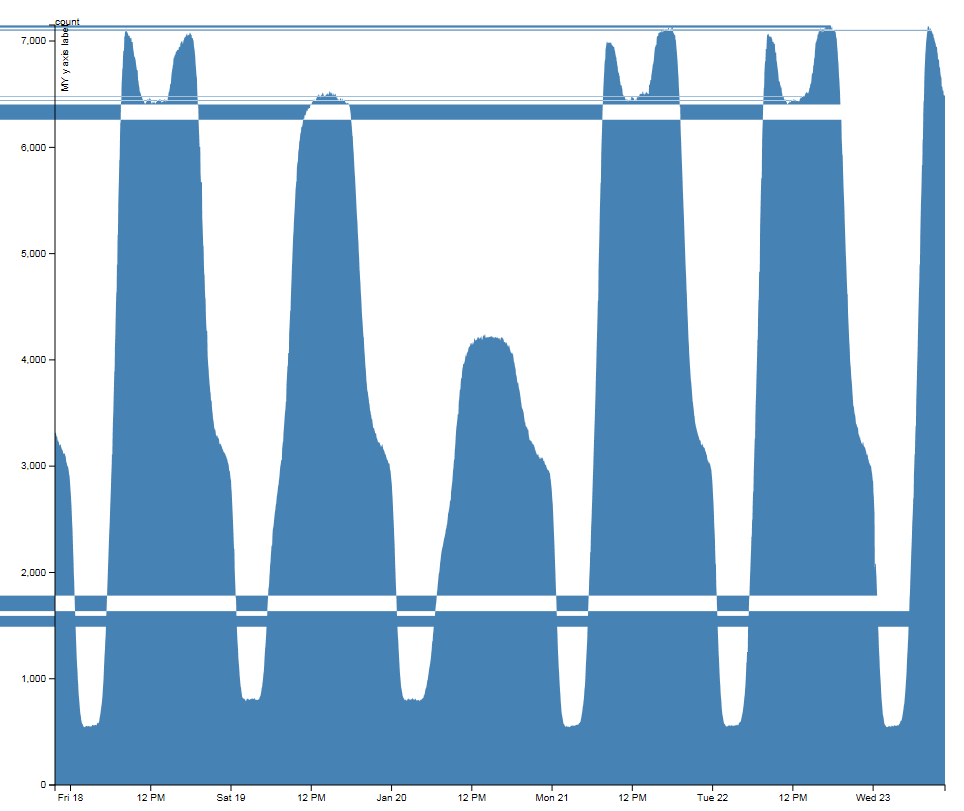
Numbers of buses running between 17 January 2013 and 23 January 2013
The graph of the number of buses running over the weekend is interesting as it doesn’t appear as if the bus numbers on the road were affected by the snow. The Saturday and Sunday difference can be seen very clearly and the morning and evening rush hours for the weekdays are clearly visible despite the annoying horizontal lines.