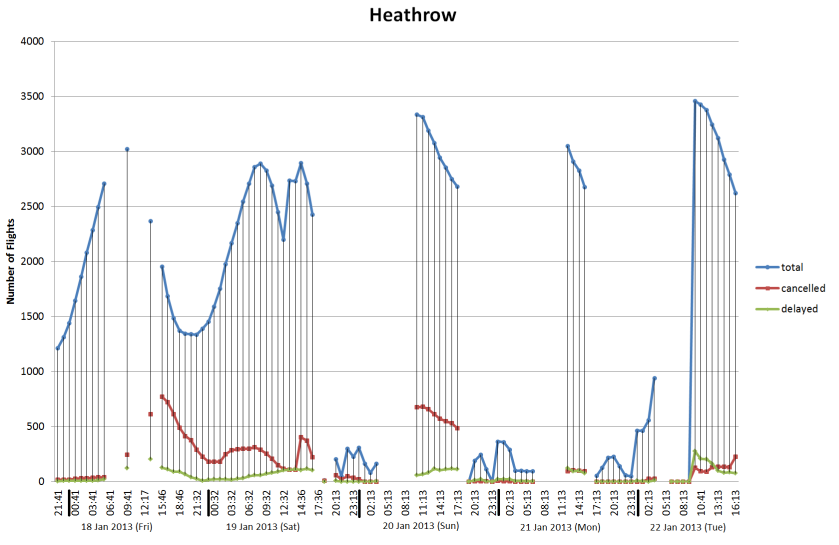
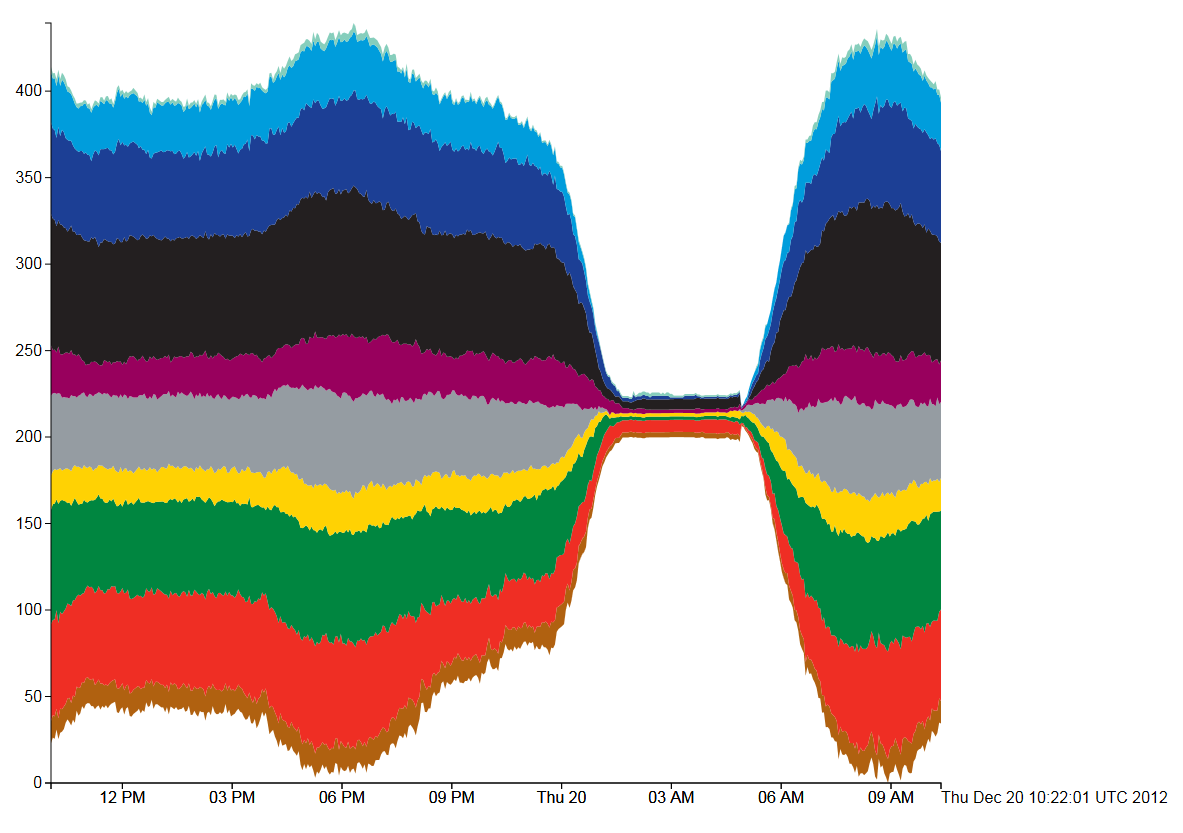
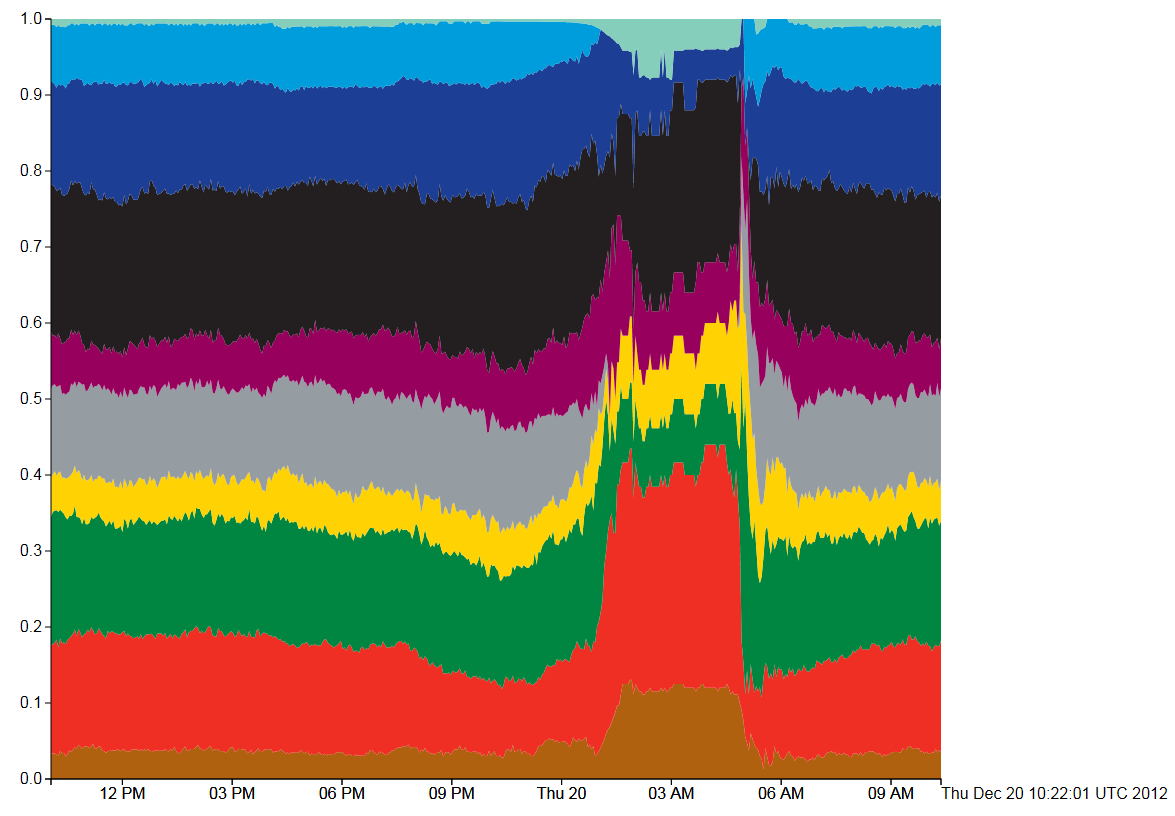
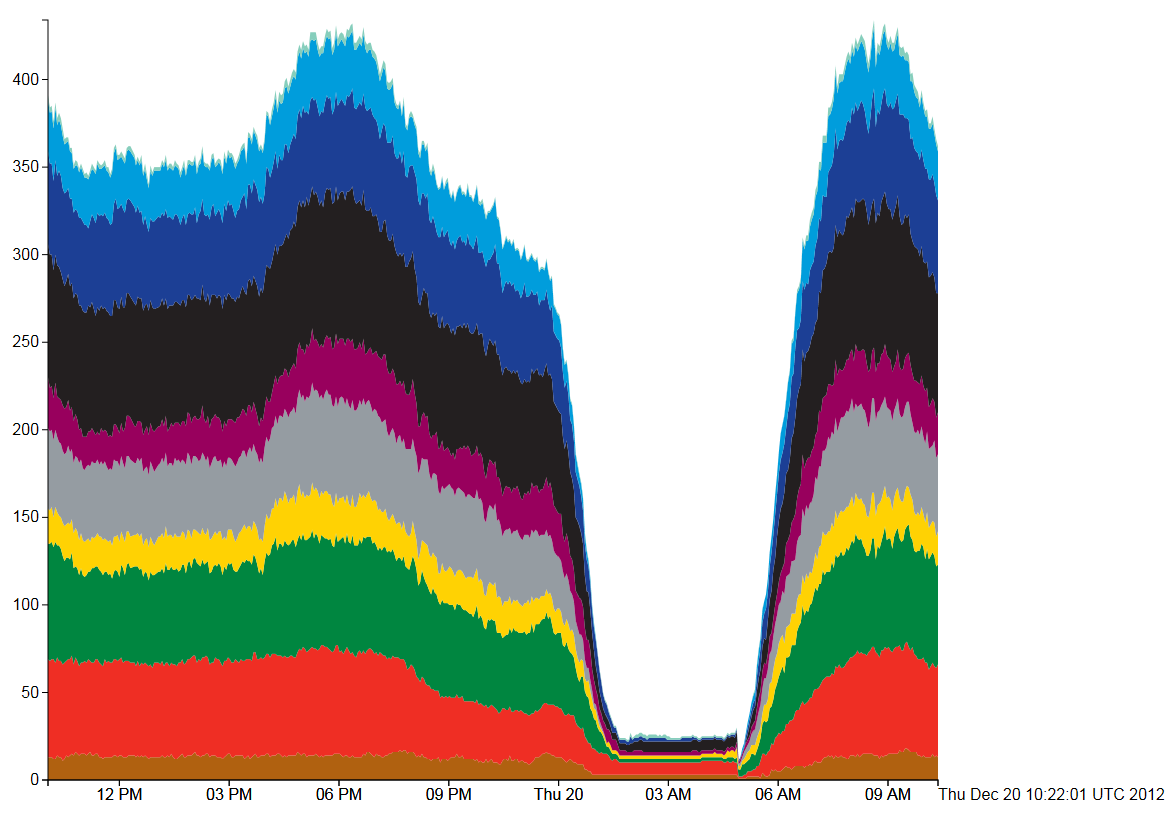
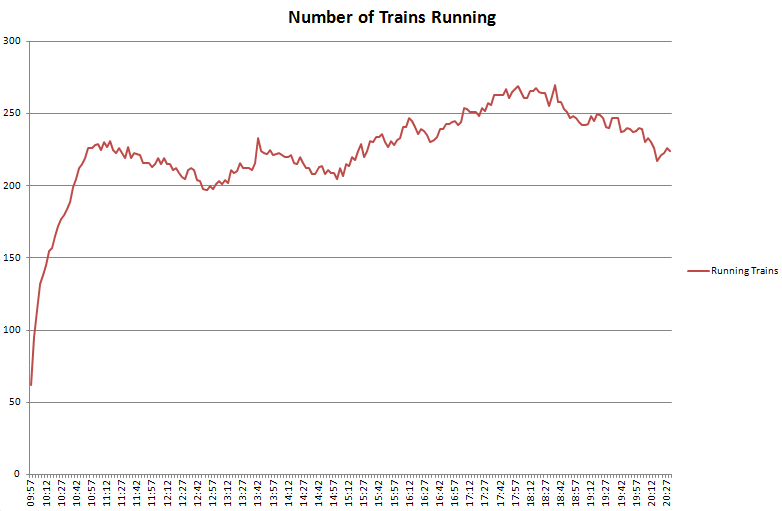
It’s been very quiet over Easter and I’ve been meaning to look at 3D visualisation of geographic data for a while. The aim is to build a framework for visualising all the real-time data we have for London without using Google Earth, Bing Maps or World Wind. The reason for doing this is to build a custom visualisation that highlights the data rather than being overwhelmed by the textures and form of the city as in Google Earth. Basically, to see how easy it is to build a data visualisation framework.
After quite a bit of experimentation, the results are shown below:
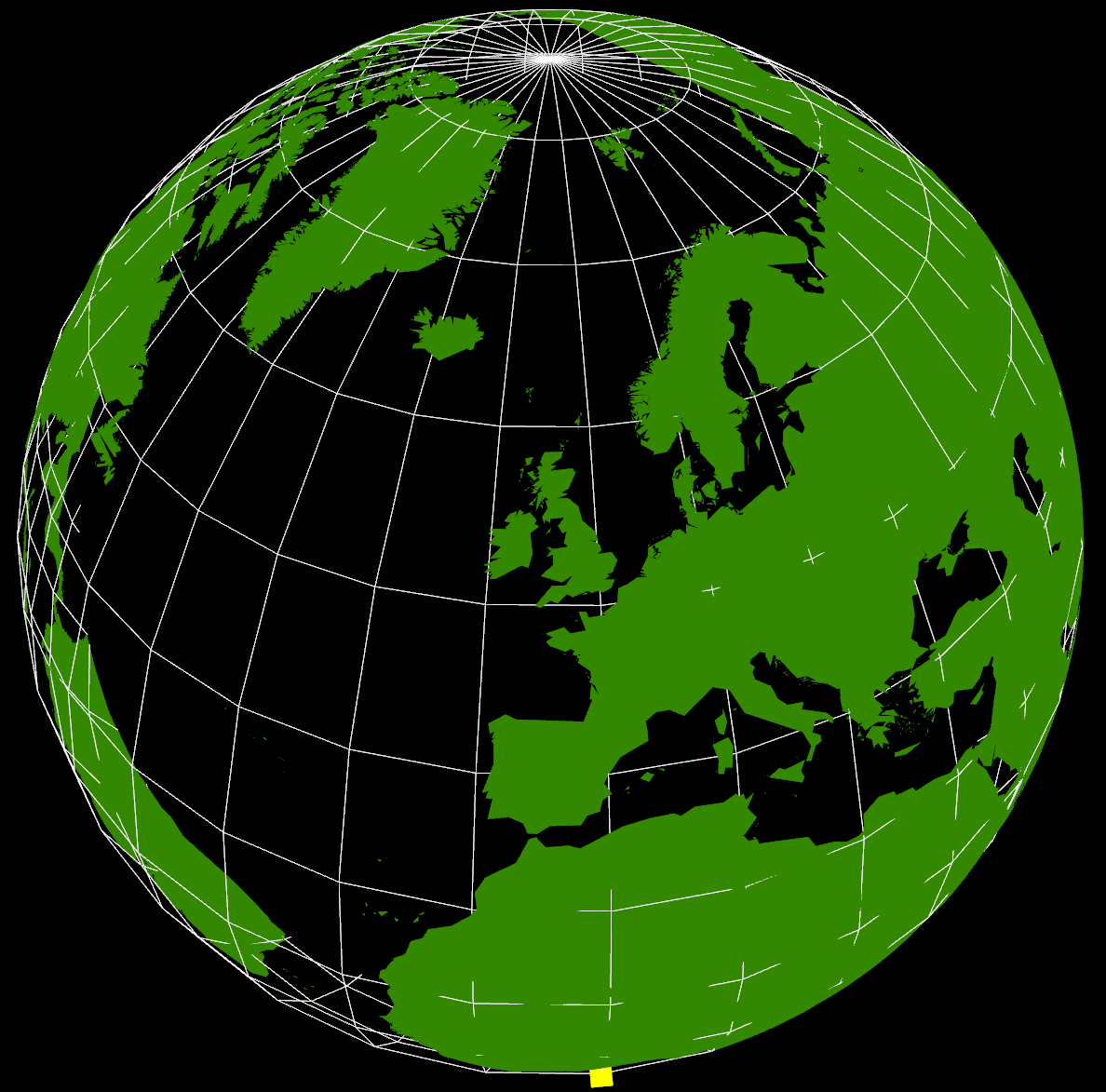
The yellow cube at the extreme southern point is marking (0,0) (lat,lon) as a reference. It’s also possible to see right through the Earth as I haven’t put any water in yet, but that’s not immediately apparent in this screenshot. The globe can be rotated and zoomed using the mouse, so it’s possible to see an area in more detail.
The way this has been constructed is as a WebGL application using THREE.JS running in Chrome. Originally, I started looking at using WebGL directly as I wanted to be able to create custom shaders, but in the end decided that programming at the higher level of abstraction using THREE.JS and a scene graph was going to be a lot faster to develop.
Where I got stuck was with the countries of the World geometry, and what you see in the graphic above still isn’t correct. I’ve seen a lot of 3D visualisations where the geometry sits on a flat plane, and this is how the 3D tubes visualisation that I did for the XBox last year worked. Having got into lots of problems with spatial data not lining up, I knew that the only real way of doing this type of visualisation is to use a spherical model. Incidentally, the Earth that I’m using is a sphere using the WGS84 semi-major axis, rather than the more accurate spheroid. This is the normal practice with data at this scale as the error is too small to notice.
The geometry is loaded from a GeoJSON file (converted from a shapefile) with coordinates in WGS84. I then had to write a GeoJSON loader which builds up the polygons from their outer and inner boundaries as stored in the geometry file. Using the THREE.JS ‘Shape’ object I’m able to construct a 2D shape which is then extruded upwards and converted from the spherical lat/lon coordinates into Cartesian 3D coordinates (ECEF with custom axes to match OpenGL) which form the Earth shown above. This part is wrong as I don’t think that THREE.JS is constructing the complex polygons correctly and I’ve had to remove all the inner holes for this to display correctly. The problem seems to be overlapping edges which are created as part of the tessellation process, so this needs more investigation.
What is interesting about this exercise is the relationship between 3D computer graphics and geographic data. If we want to be able to handle geographic data easily, for example loading GeoJSON files, then we need to be able to tessellate and condition geometry on the fly in the browser. This is required because the geometry specifications for geographic data all use one outer boundary and zero or more inner boundaries to represent shapes. In 3D graphics, this needs to be converted to triangles, edges and faces, which is what the tessellation process does. In something like Google Earth, this has been pre-computed and the system loads conditioned 3D geometry directly. I’m still not clear which approach to take, but it’s essential to get this right to make it easy to fit all our data together. I don’t want to end up in the situation with the 3D Tubes where it was written like a computer game with artwork from different sources that didn’t line up properly.
The real reason for building this system is shown below:

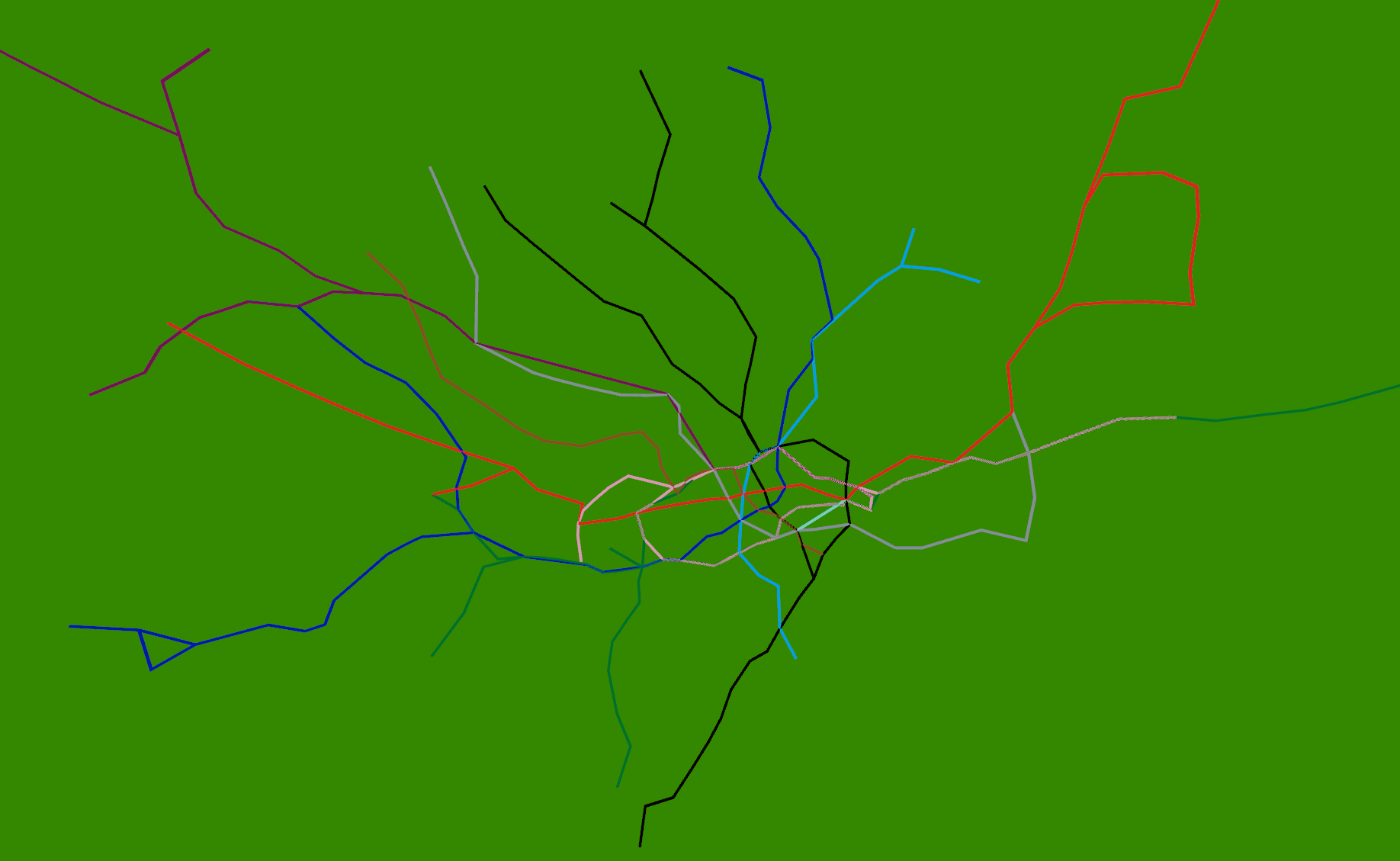
Strangely enough, adding the 3D tube lines with real-time tubes, buses and trains is easy once the coordinate systems are worked out. The services to provide this information already exist, so it’s just a case of pulling in what is relatively simple geometry. The road network and buildings are available from the OS Free data release, so, with the addition of Lidar data, we could build another (real-time) Virtual London model.
Just for the record, it took about 4 days to get this working using the following tools: Visual Studio 2010 C# and C++, Autodesk 3DS Max 2012 and the FBX exporter, Python 2.6, NetBeans Java and Geotools 8, Quantum GIS, Chrome Developer Tools